

安装相应所需的第三方库,在网页上找到微博热搜榜,用F12找到标题的位置:td-02

最终爬取结果: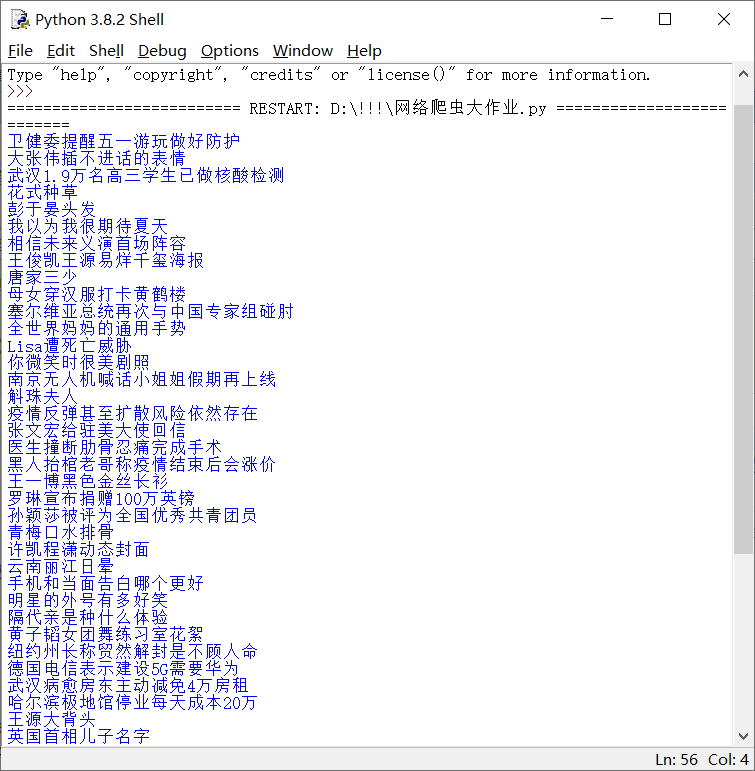
源代码:
import requests
from bs4 import BeautifulSoup
import bs4
url = "https://s.weibo.com/top/summary?cate=realtimehot"
def getHTMLText(url):
try:
kv={"User-Agent":"Mozilla/5.0"}
r = requests.get(url, headers=kv, timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "error"
html = getHTMLText(url)
soup=BeautifulSoup(html,'html.parser')
sou = soup.find_all("td",class_='td-02')
name = []
for x in sou:
print(x.a.string)
在最后附上漏了的第二次作业: 代码:
代码: